Multimodal Voice AI Agents
Multimodal Voice AI agents combine speech and text to create natural, context-aware, and proactive interactions, transforming customer support and operational efficiency.

Introducing 3CLogic's Multimodal Voice AI Agents
3CLogic's multimodal AI agents can understand and process both spoken language and typed text inputs concurrently, delivering frictionless experiences in real time.
Multimodal Voice AI
Customer Service Example Flow

John
received his order confirmation.

Identifies caller, finds order, and
confirms phone number to activate a messaging channel.
"I see your email is missing."
"Here is a list of your order."
"Lets confirm the shipping address."
"I've sent a summary for your review."
Allows caller to type their email address.
Allows caller to select from a visual list of options.
Sends location-finder to update address.
Confirms the new order details.
Provides context to the Multimodal AI Agent at every step.
"I see your email is missing"
"Here is a list of alternative options available."
"Lets update the shipping address you would prefer."
"I've sent a summary for your review."
Allows caller to type their email address.
Allows caller to select from a visual list of alternative options.
Dynamically sends location-finder to easily update delivery address.
Confirms the new order details.

The Multimodal Value
The limitations of traditional service channels create inherent friction in high-stakes enterprise environments. Multimodality is positioned as the solution to the specific weaknesses of standalone voice and digital platforms.
- The Voice Constraint: While intuitive for complex problem-solving, voice is inefficient for "fine print," such as reciting email addresses or alphanumeric codes.
- The Digital Constraint: Digital channels provide precision but often lack the conversational depth and nuance required for complex issues.
- The Multimodal Solution: By bridging these channels, AI agents create a "high-fidelity intelligence stream" where users can speak naturally while providing precise data via digital text or visual selections.
Deploy agents that and take action
Configure, deploy, and monitor multimodal agents in different languages across voice or chat.
Multimodal agents process voice and digital inputs simultaneously
Unlike traditional "hand-offs" where a user must stop one interaction to start another, multimodal agents process voice and digital inputs at the same time. This allows the multimodal AI agent to verify a digital input (like a serial number, email, or list of options) while the conversation continues without interruption.
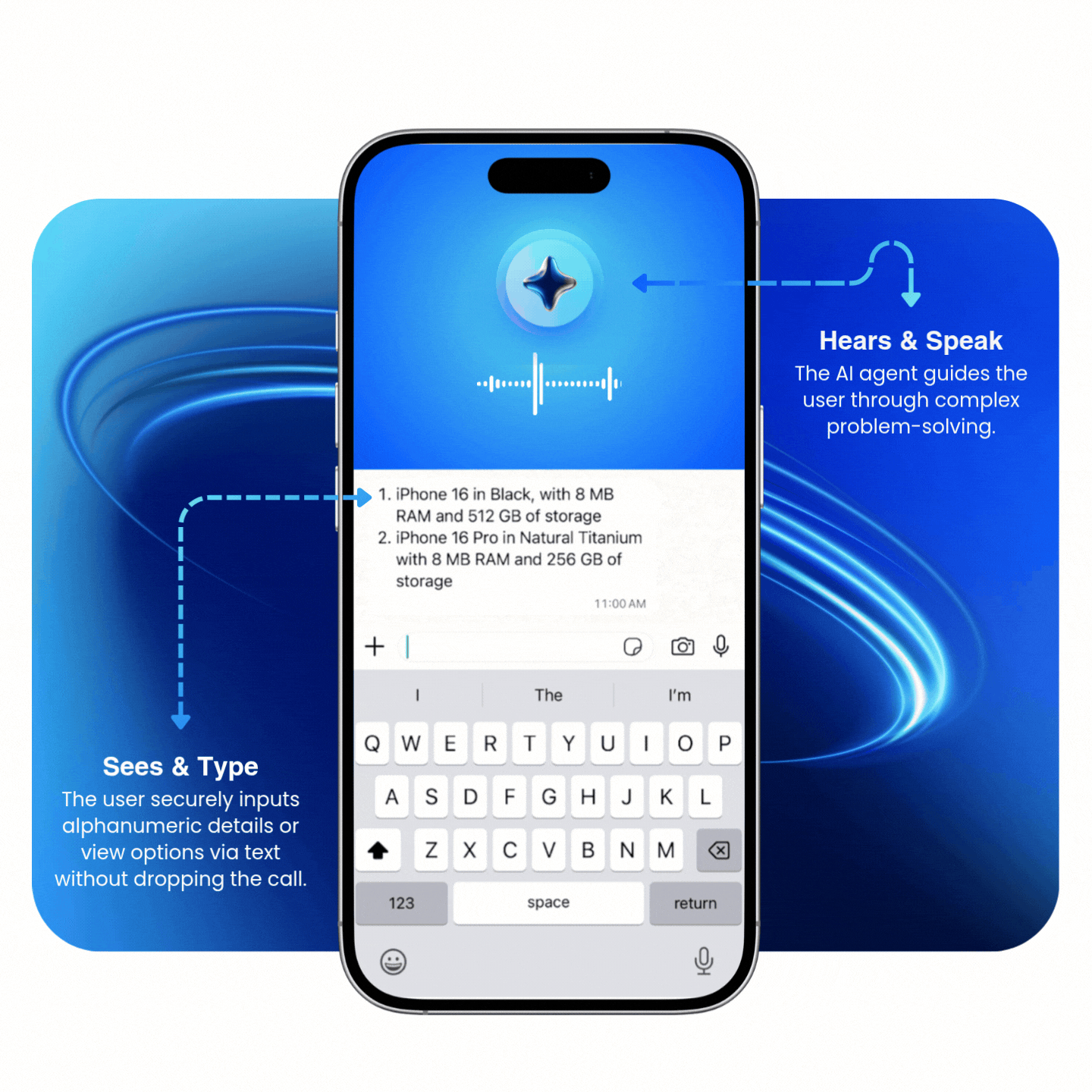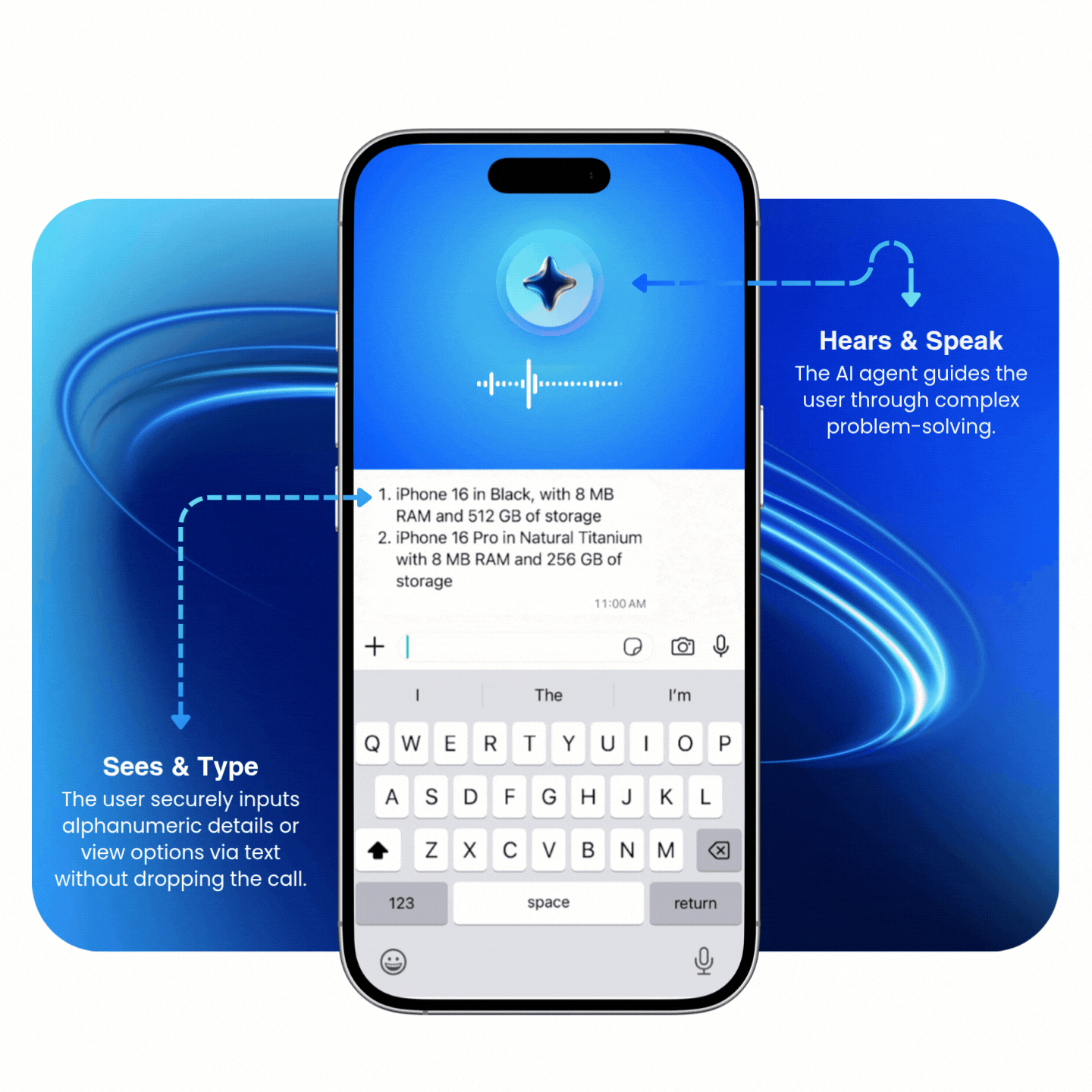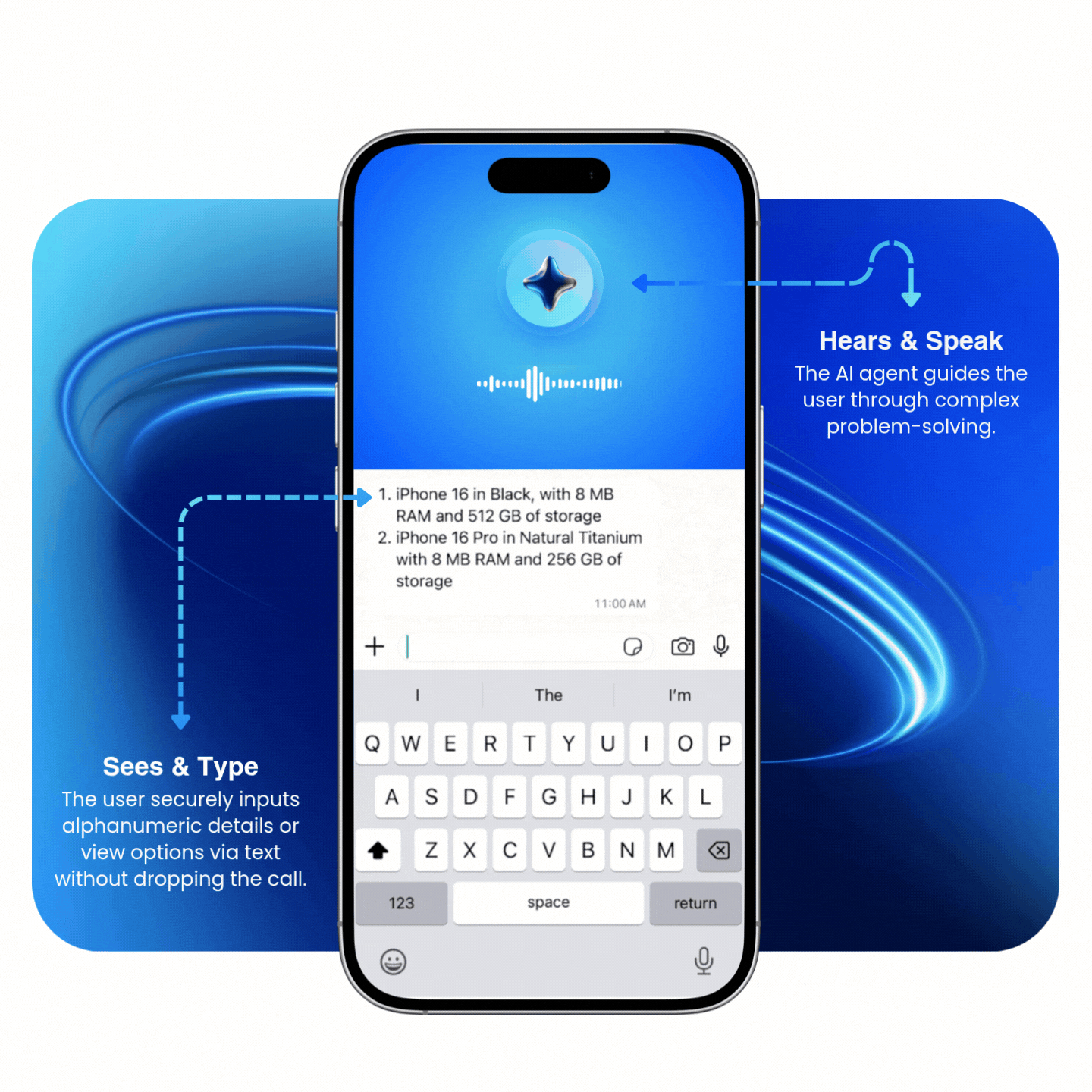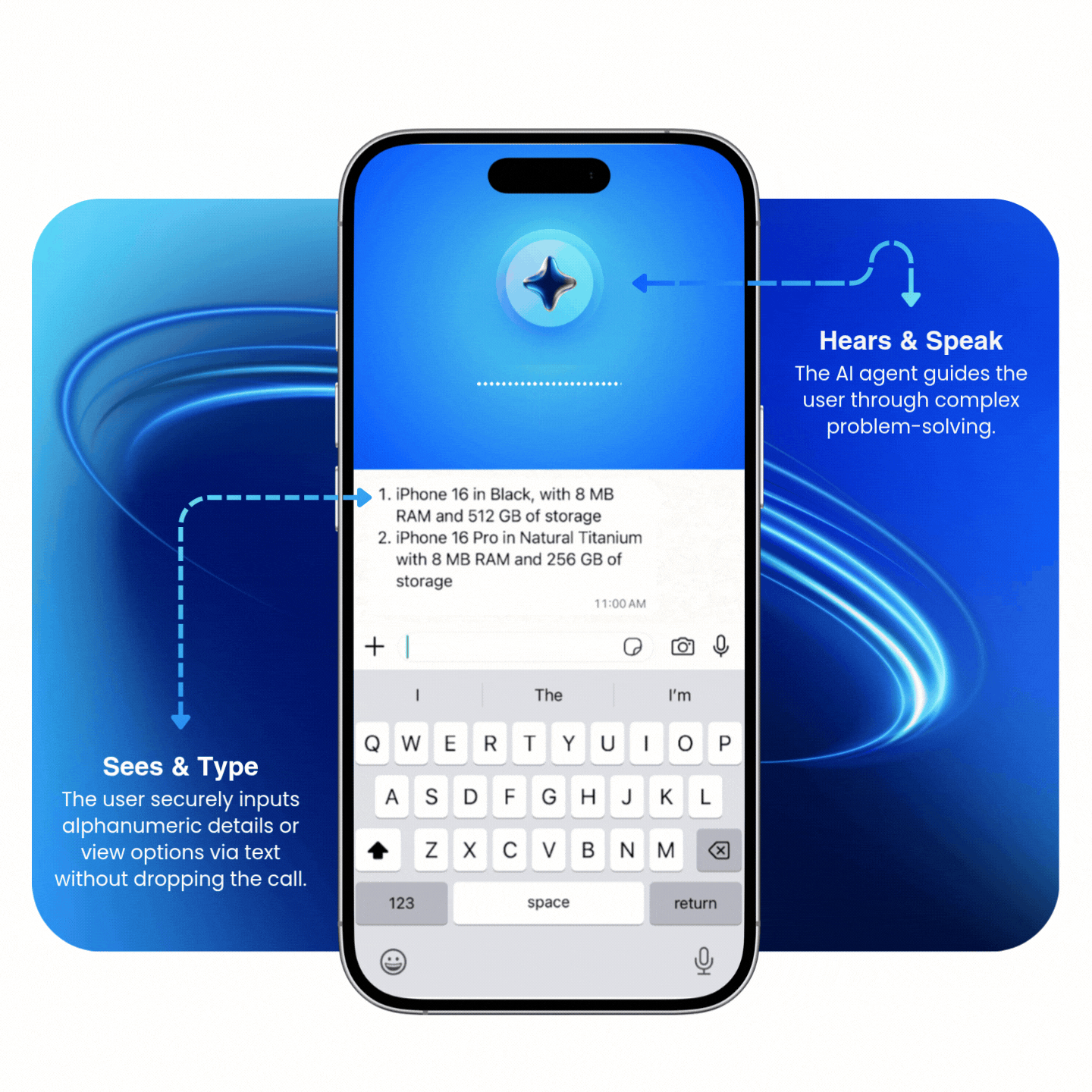
Replace tedious verbal exchanges with digital accuracy
- Alphanumeric Data: Eliminates the need for phonetic spelling (e.g., "S as in Sierra").
- Visual Decision-Making: Instead of listening to long lists of flight alternatives or appointment slots, users view and select options directly on their screens.
- Reduced Cognitive Load: Shifting data-heavy tasks to visual inputs simplifies the decision-making process for the user.

Multimodal agents mirrors natural human communication
Multimodality mirrors natural human communication, which is adaptive and non-linear. By allowing users to move fluidly between speaking and typing without losing context, the interaction feels human-centric rather than technical.

Stay in the know
Everything you need to know about the latest CX/EX news for you, your employees, and your business.


